The Question We are not asking about Computer Vision.

In Computer Vision we are at very good stage to recognize object we created models etc algorithms to image classifcation we didn't not only stop there we went ahead we also achieved succes in object localization which means given in an image we can now identify where the object is with highest accuracy to identifying dozens of other classes. But as of many challenging problem in computer which are out there. We must pause for a minute and ask question what all can we do with state of the art and what more can we contribute to it? But we must think, although we have achieved so much good in computer vision what all we can do with it. Given a problem with in computer vision lets say given a store, the store manages wants to evaluate the broad varieties of customer walk in so they can target there customer with wide range of products. I know what you are thinking install a camera at the gate of start collecting your data on wide range of classed young, adult, mature,old or by the age group so that its more appealing to business problem. But, think for a minute there is so much you have to do apart from the creating model. for ex:
You have to evaluate the customer only on entering the store not to counts them twice.
Your models should be robust such that it count the number of customer for each class and create database of it.
You also have to take care of burgalary, shoplyfting some mischivieos activity etc
The point that I want to convey is, there is more than AI job you have to do here than simply doing a computer vision task i.e lot of coding and algorithms to test. But it certainly sound obscure to me. When I learned machine learning a diagram was in the slide which is resting in my mind since then, which is: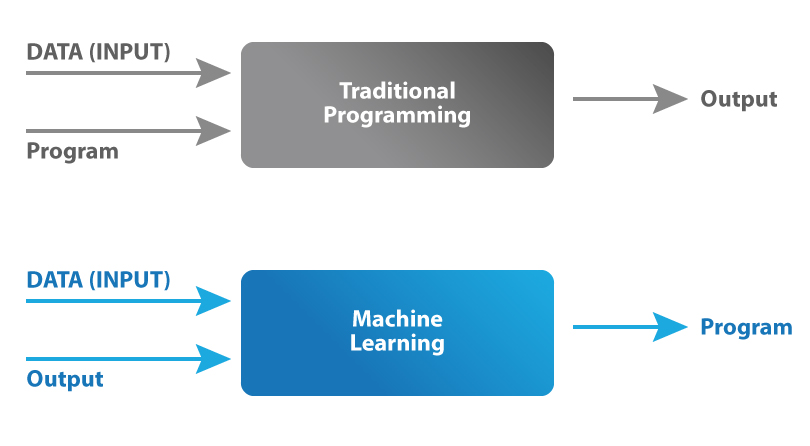
Here is one such thing I came across with, Visual Question Answering or VQA which started in 2010 if I am not wrong, www.vizwiz.org is the site which hosts the challenge every year. The concept is similar to image captioning but I am not going that road to tell the differences. Here the task is very specefic and challenging the job is to make world a better place for visually impaired people. That is given a task it should match clearly to the real world with context.
YES! Context
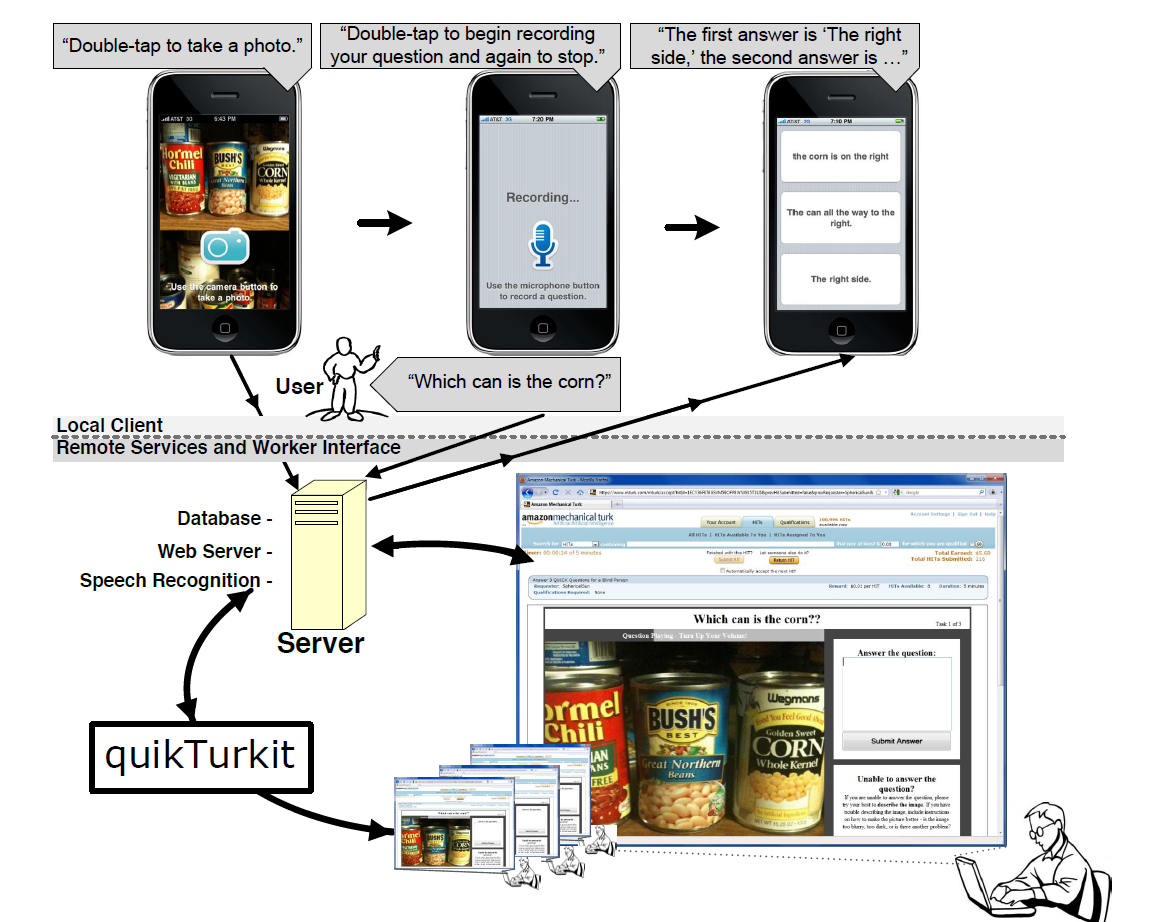 If you ask any machine learnig enthusiast to develop an application for visually impaired person or blind person the de facto answer I got is "Use computer vision and let the model speak out what is in front of" this sounds reasonable. But the thing we are missing what challenges where a blind person come across what are the struggles they face everyday, does this model is going to solve the problem. The paper I discussing is from vizwiz.org https://www.cs.cmu.edu/~jbigham/pubs/pdfs/2010/vizwiz.pdf which is VizWiz: Nearly Real-time Answers to Visual Questions. But before that look at the given picture below
If you ask any machine learnig enthusiast to develop an application for visually impaired person or blind person the de facto answer I got is "Use computer vision and let the model speak out what is in front of" this sounds reasonable. But the thing we are missing what challenges where a blind person come across what are the struggles they face everyday, does this model is going to solve the problem. The paper I discussing is from vizwiz.org https://www.cs.cmu.edu/~jbigham/pubs/pdfs/2010/vizwiz.pdf which is VizWiz: Nearly Real-time Answers to Visual Questions. But before that look at the given picture below 
The VQA is the intersection of CV, ML, NLP and Reasoning. Don't get intimidated by the concepts you have to learn. It sounds fun you are trying to solve it.
Now, VQA
Basically it first devloped on mobile devices 10 years back the ascnesion of smartphone has just started. With iphone 3GS.
It was develop to ask question by the user expecting a response what's in front of it. The best part of the paper I liked about it the paper talked about generalized model which will be totally vague. The author used the term SKILL they targeted on a specific skill to monitor the problem.For example: a visually challengedd person is buying grocery.
This sounds reasonable and doable and seems like we could solve the problem.
Let me stop you there, you are still not thinking yourself what are the problems he may come across.
Like,
What is the product he wants to buy
what is the expiration of the product
If its apparel what size and color it is.
what is the correct bill I am paying i.e identifying the currency.
This is the best part of the paper they tried to answer, Think how a blind person can use the camera, they found out that (11.0%) of the images taken were too dark for the question to be answered, and 17 (21.0%)
were too blurry for the question to be answered. It blows my mind how a blind person will know how to focus and what simply srufacing the camera towards it is not going to give answers. Look at the image below

 The given images shows the quality of image taken by them and how it is difficult for them to get things straight from real world.
There is more to images which in this blog post is not possible. I will keep posting regarding VQA like how to solve, the architecture, how the datasets look like etc.
The given images shows the quality of image taken by them and how it is difficult for them to get things straight from real world.
There is more to images which in this blog post is not possible. I will keep posting regarding VQA like how to solve, the architecture, how the datasets look like etc.