Why Data Definition is Hard ?

Here is the scenario. You picked up a Data Science project you researched thoroughly and even better you decided to work in a team. You go went through the data science pipeline as it is supposed to be. Instead of taking academic data you decide to do your own data collection.
But here is a caveat;
Welcome, I am in my last week of 1st module of Machine Learning in production. And the genius Andrew Ng mesmerizes me with the ‘question why data definition is hard’ and how it could affect model performance. Given the task of labelling the data the task doesn’t sound much of a deal than tedious and cumbersome, here you simply you instruct people about labelling. In fact it’s the not the way we think. In his opening lecture he describes a lot wrong can happen with labelling inconsistency, before he jumps to main the part he properly discusses to we must define an input “ X” for example. You have images of mobile phones from industry where the problem is to rule out the phones with scratches on it. But during the labelling you found out that some of the image taken is very hard for even human to find out at first sight.
If you are thinking you to label in spite of that then YOU ARE WRONG.
The correct thing to do is go back to the factory and tell them to improve the lightening condition.
Sometimes if your sensor or your imaging solution or your audio recording solution is not good enough, the best thing you could do is recognize that if even a person can't look at the input and tell us what's going on, then improving the quality of your sensor or improving the quality of the input x, that can be an important first step to ensuring your learning algorithm can have reasonable performance.
Even he concluded further that not only you focus on input 'x' you also have to figure out what should be the target label y ? WHY 'Y' ? Keep reading to know more about label inconsistency.


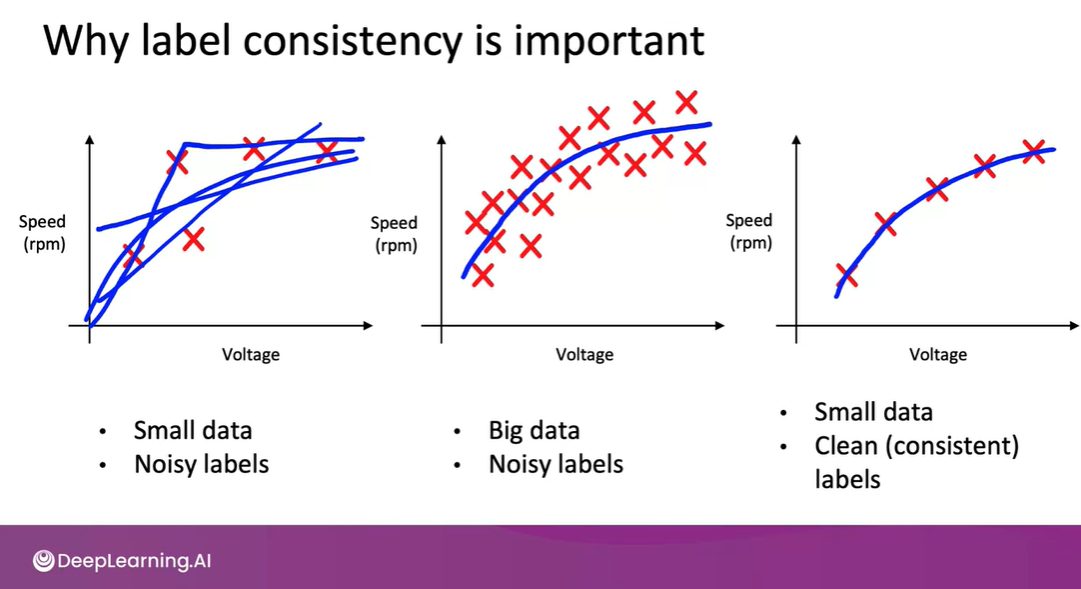
Humans are good at labelling data, in fact unstructured data but there is certain limitations to it one thing is exponential growth of data and the other thing is label inconsistency. That seems plausible here is why, given a problem statement it requires millions of data to work but the data doesn't comes in its purest form its unstructured and it require human intervention to label. And it's better to have 10,000 clean labels than 1,00,00,00 inconsistent labels. And it takes huge amount of time and human power to label it that’s why we have things like data augmentation. So one thing you can do to solve this problem is emphasis in data process, in terms of how you collect and install the data. Then you can just give proper instructions to crowd source labellers.
Label inconsistency
Even though, you used proper conventions to label your data. There might still be a problem all I am saying is this doesn't apply to every problem suppose if you have image labelling task and the data is huge and you setup a team to label it one might label scratches in mobile differently and other included multiple scratches in one bounding box, there label inconsistency happens. And if you have a 100 labelers or even more, it's just harder to get 100 people into a room to all talk to each other and hash out the process. And so you might have to rely on a smaller team to establish a consistent label definition and then share that definition with all, say 100 or more labellers and ask them to all implement the same process.
There is more to just labelling the data. It requires proper thought and decision making process to narrow it down to a proper solution.
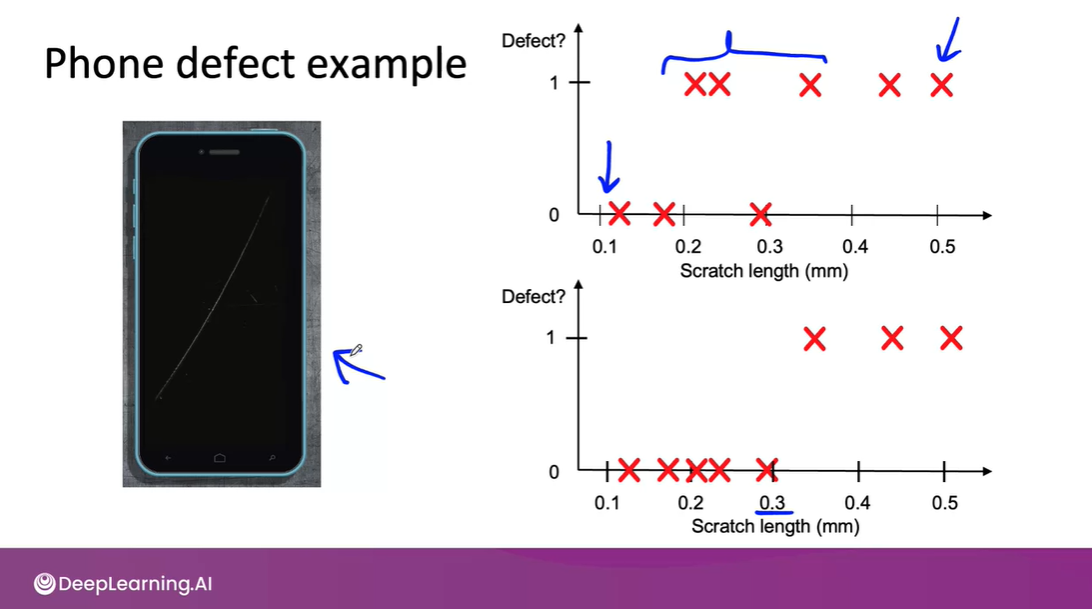
Here's a general process you can use. When you find that there's disagreements, have the people responsible for labelling, this could be the machine label engineer, or it could be the subject matter expert, such as the manufacturing expert that is responsible for labelling what is a scratch and what isn't a scratch, and/or the dedicated labellers, discuss together what they think should be a more consistent definition of a label y, and try to have them reach an agreement. During this discussion, in some cases the labellers will come back and say they don't think the input x has enough information. Another common decision that people an engineer could use is merging classes. For ex: In phone scratches you label deep scratches on the surface of the phone, as well as shallow scratches on the surface of the phone, but if the definition between what constitutes a deep scratch versus a shallow scratch, barely visible here I know, is unclear, then you end up with labellers very inconsistently labelling things as deep versus shallow scratches. Sometimes you don't really need to distinguish between these two classes, and you can instead merge the two classes into a single class, say, the scratch class, and this gets rid of all of the inconsistencies with different labellers labelling the same thing, deep versus shallow. Merging classes isn't always applicable, but when it is, it simplifies the task for the learning algorithm. Let me use speech illustration to illustrate this further. Given the audio clip, You really can't tell what they said. If you were to force everyone to transcribe it, some labellers would transcribe, "Nearly go." Some maybe they'll say, "Nearest grocery," and it's very difficult to get to consistency because the audio clip is genuinely ambiguous. To improve labelling consistency, it may be better to create a new tag, the unintelligible tag, and just ask everyone to label this as nearest unintelligible. This can result in more consistent labels than if we were to ask everyone to guess what they heard when it really is unintelligible. You can observe this example in your YouTube auto captioning where sometimes model is not able to predict the word and it throws gibberish, well know you know it’s a label.

Well is depends on the purpose of your problem. If your goal is for proxy for bayes error
Bayes error rate is the lowest possible error rate for any classifier of a random outcome (into, for example, one of two categories) and is analogous to the irreducible error.
Then you can go with the proxy for bayes error that will 0.5 %
But when you definition human level performances changes to some level of context like you only want to surpass the single radiologist then you can go with 1 % error. But sometimes your HLP or due to lack of industrial skill the human level performance bar is set very low, and in that terms there is no point of having 99% accuracy. But one must ask question "Even these labels are done by humans" this could hurt HLP and can also put a false benchmark. For example:In speech recognition task 70 % of people have annotated data differently and 30 % of data have labelled the same type of data differently the fact is both of the data is fine and the difference is not that much, but here agreeing one type of labelling is so much that it hurts the goal of problem statement. By having label inconsistency it masks or hide the fact that you're learning algorithm is actually creating worse transcripts than humans actually are. And what this means is that a machine learning system can look like it's doing better than HLP. But actually it producing worse transcripts than people because it's just doing better on one type of problem which is not important to do better on while potentially actually doing worse on some other types of input audio.

To wrap it up we must focus on cleand data and labelling. Unstructured data is prone to lable inconsistency. Having a small team and agreeing on one label description is always a plus sign.