ML Data Is A First Class Citizen

- In production environment it is just drop in the ocean.
- ML Pipelines
- Hello World.... TFX
- Data and concept change in production ML
- Data Labelling- Process Feedback and Human Labelling
- Model Decay
In My last post in context with Machine Learning in Production I discussed Why Data Defination Is Hard in this post I am going to discuss why you should treat your data as First class citizen. Data is the hardest part of ML and important piece to get it right. Data in academic or research environment is quite different from the Production environment. Before moving any further Production ML in short is a combination of ML development and modern software development practices. Well in academia it's fairly simple you get standard dataset fairly cleaned and labelled, you optimize it and evaluate the result. Once you are happy with the result you are typically done. In production environment it ML code is just a drop in the ocean.
In production environment it is just drop in the ocean.
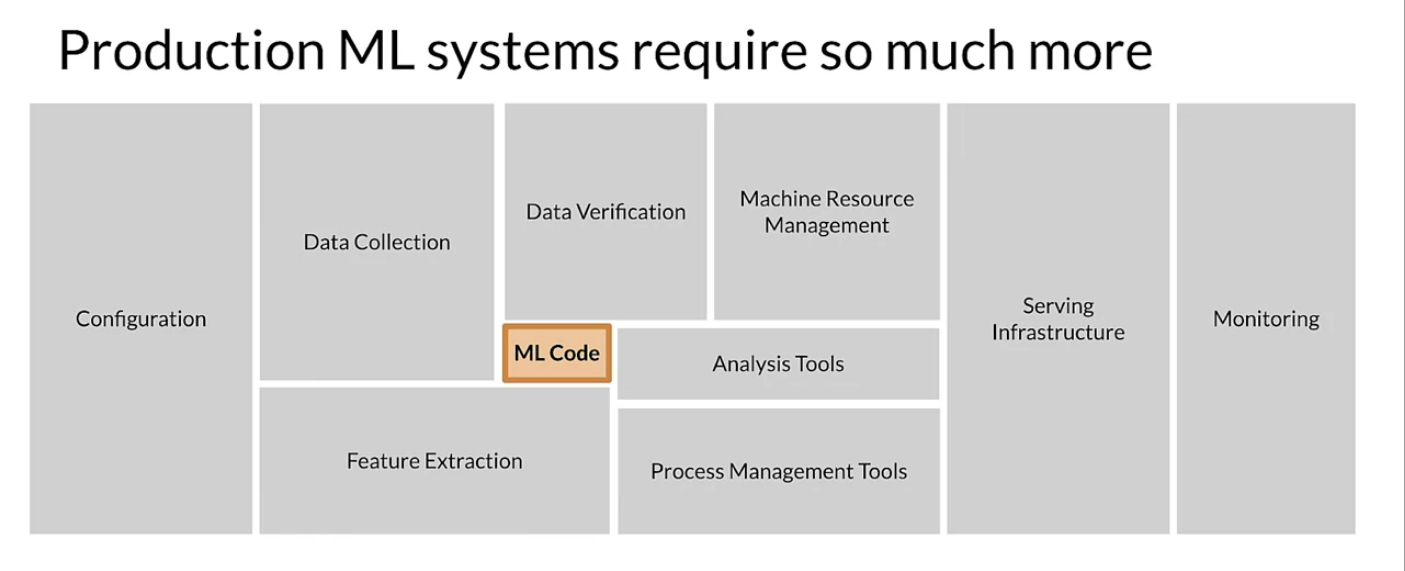
The reason why production ML (from now onwards I will use MLOps) is most vulnerable and the reason it’s most important aspect is that the data is dynamic and usually shifting. It would be fair to say that you can look at Production Machine Learning as both machine learning itself and the knowledge and skillset required and modern software development. It really requires expertise in both areas to be successful, because you're not just producing a single result; you're developing a product or service that is often a mission critical part of your offering. We deploy it, maintain it, and improve it so that we can make them available to our users and user businesses.
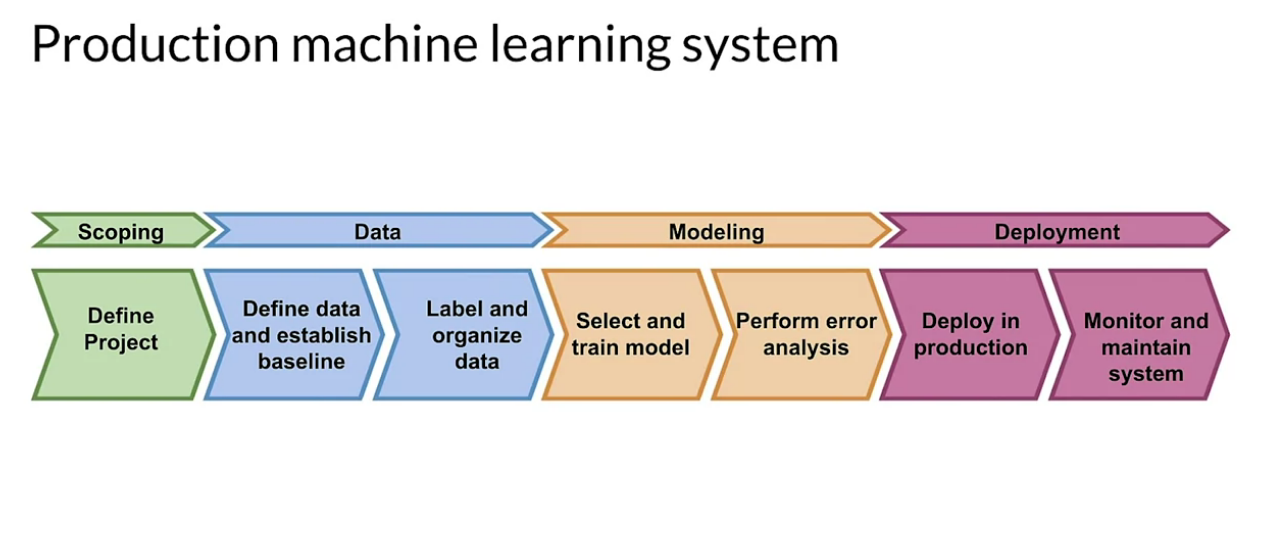
Adopting a model is much more important task than understand the ML algorithm. For any given problem, understanding the problem statement is the first step in finding the solution. Similarly, scoping in MLOps which focuses on defining the project needs and goals and the resources required to achieve them. Next, you start working on your data, which defining the features that you're going to use well as organizing and labelling your data. That may sometimes include measuring human level performance to set a baseline for comparison. Then you design and train a model. In this phase, error analysis will help you refine your model to suit your project's needs. After training your model, you deploy it so that it can be used to serve prediction requests. You have available options like, mobile devices, on a Cloud, or in IoT devices, or even in a web browser.
One thing every Data scientist or ML engineer must know the fact that Your data will change Over time well there are different types of it that I will discuss later. So keep in mind that real-world data continuously changes, which can result in a degradation of your model performance. You need to continuously monitor the performance of your model, and if you measure a drop in performance, you need to go back to model retraining and tuning, or revise your data. During deployment, new data may affect your project design either positively or negatively and risk coping might be necessary. Ultimately, all these steps create your production ML system, which needs to run automatically such that you're continuously monitoring your model performance, ingesting new data, and retraining as needed, and then redeploying to maintain or improve your performance. Keeping these things in mind will help you automate the whole process, it seems daunting but don't worry I will discuss the methods and methodologies for doing this.
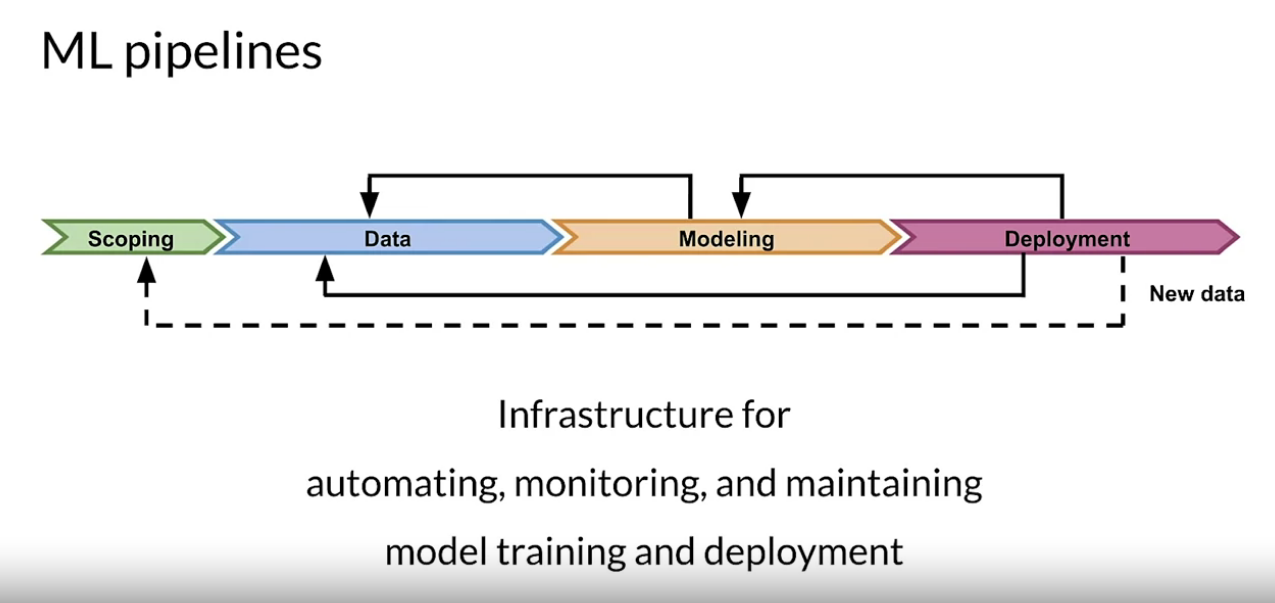
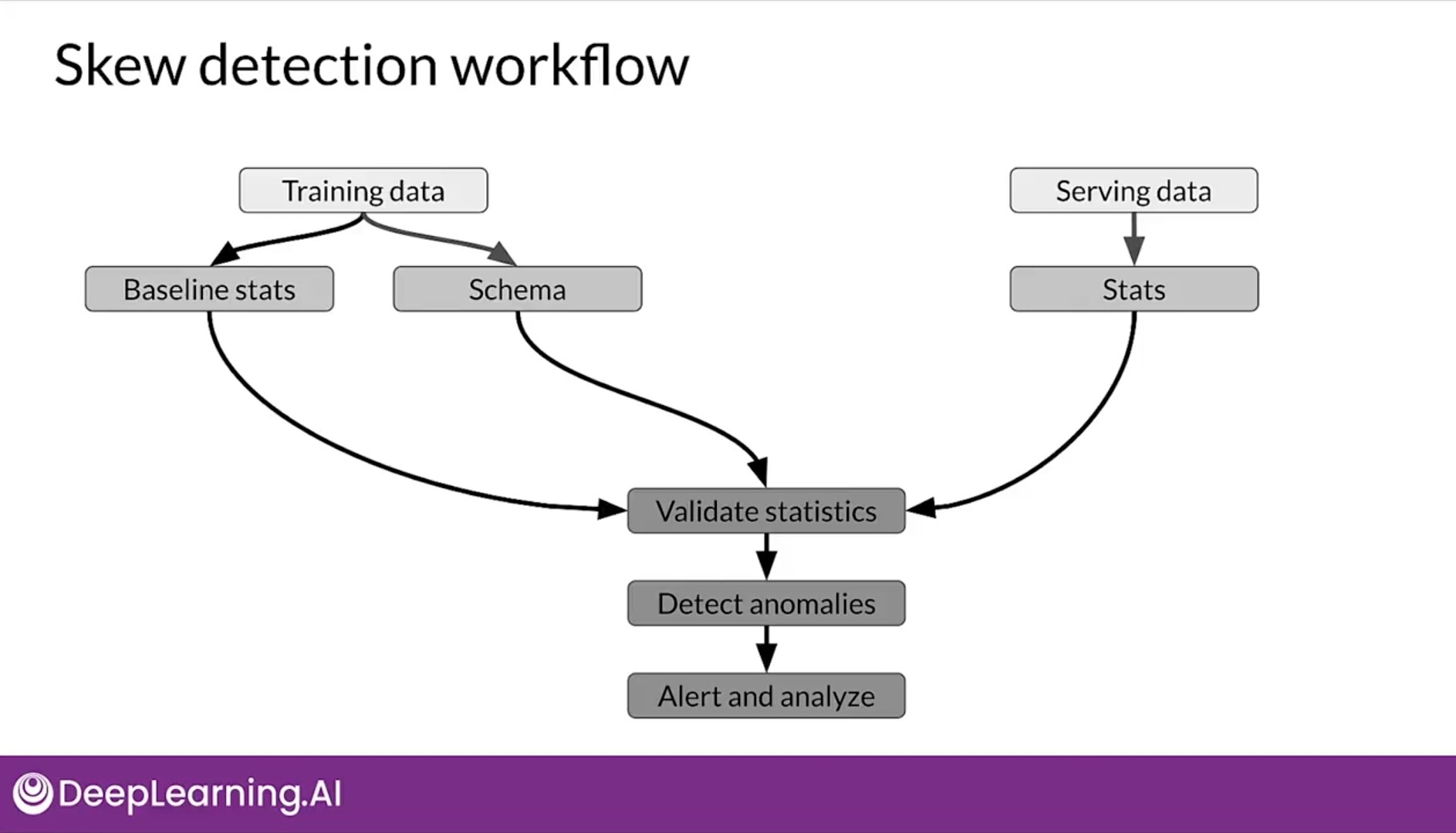
Thanks to many open source community out there to implement ML pipelines one such open source library we have is Tensorflow Extended. As soon you start using TFx for production you will realise how important these libraries are. Now let us discuss how pipelines orchestration sequence and schedule ML tasks to implement the entire ML training process. But you must ask question What is ML Pipeline?, it's easy just remember the above diagram, the ML in production is an iterative process, keeping your code static more on data driven technique you have to work back and forth every time when there is some new finding or shift in the data. Sometimes you have to redo the scoping (which is defining the needs, goals and resources.) But you can't stop every time when there is new data. The pipeline above is all about automating, monitoring, and maintaining this ML workflow from data to a trained model. ML Pipelines form a key component of MLOps architectures.
Orchestrator is responsible for scheduling the various components in ML pipelines whereas on the other hand TFX Pipeline is a sequence of scalable components that can handle large volumes of data.
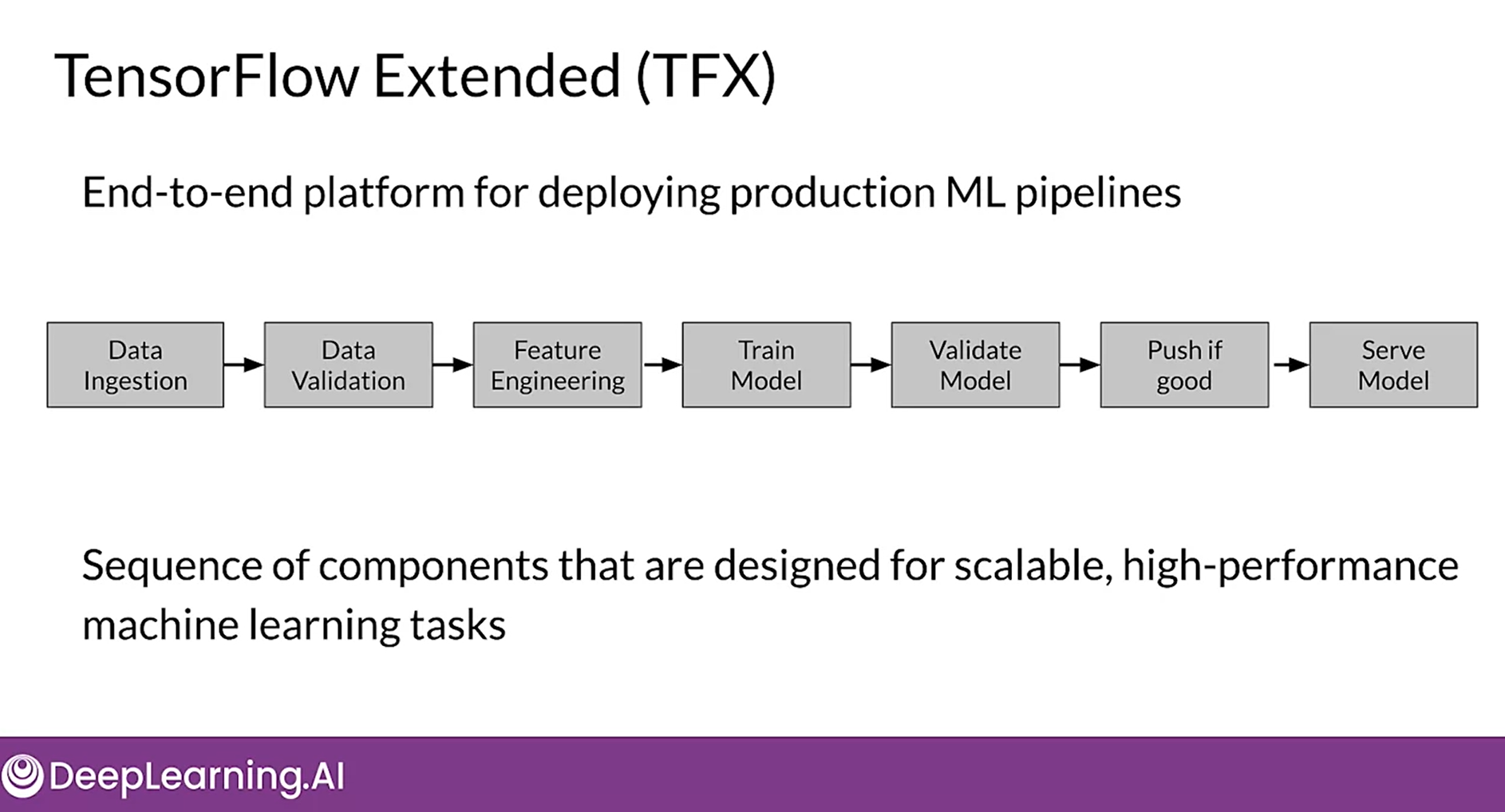
Starting on the left, we follow the process as given till the training point then we validate it. If it's better than what we already have in production, we're going to push it to production. Finally, we're serving predictions. The sequences of components are designed for scalable high performance Machine Learning tasks. TFX help you to implement that, TFX in production components are built on top of open-source libraries, such as Tensorflow Data Validation.
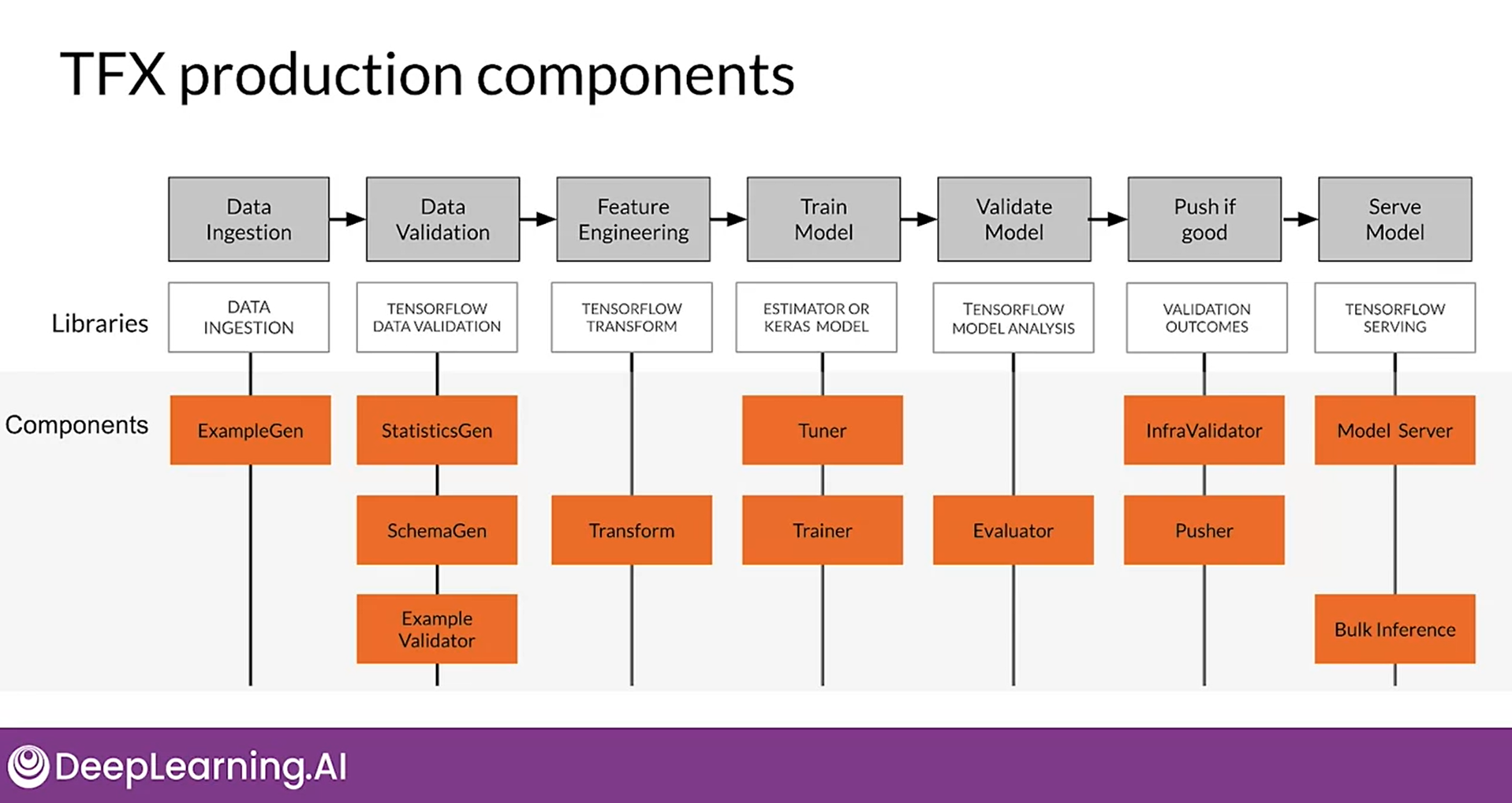
Components in the orange here, leverage those Libraries and form your DAG as you sequence these components and set up the dependency between them, you create your DAG, which is your ML Pipeline.
Hello World.... TFX
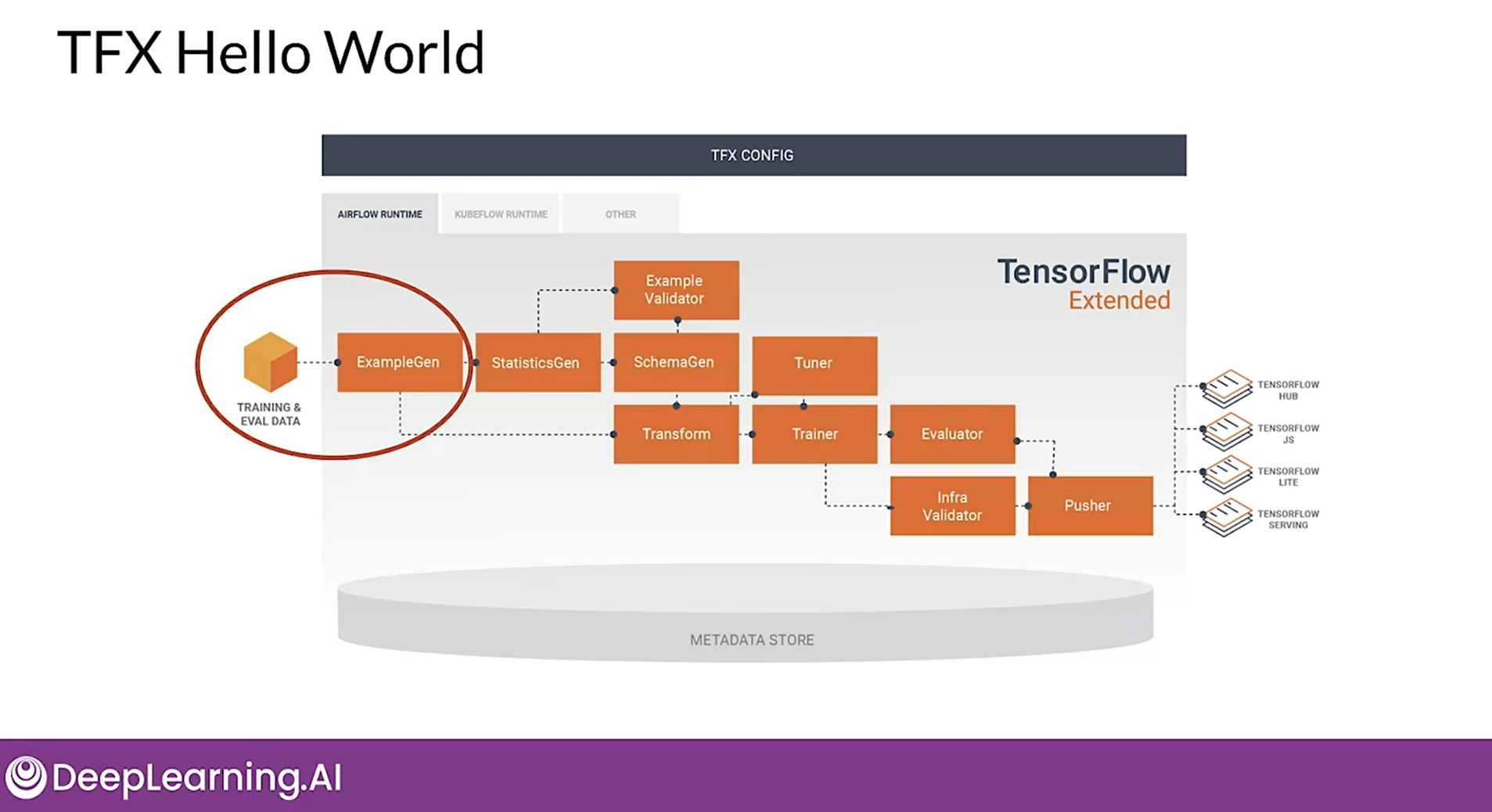
This is what we refer to as the Hello World of TFX. We start on the left with our data and we're going to ingest our data with a TFX component called ExampleGen. All the boxes in orange that you see here are TFX components. In fact, these are components that come with TFX when you just do a PIP install. Next, we generate statistics for our data. We want to know the ranges of our features, if they're numerical features, if they're categorical features, we want to know what are the valid categories and so forth. What are the types of our features? Example Validator is used to look for problems in our data. SchemaGen is used to generate a schema for our data across our feature vector. Transform will do feature engineering. Tuner and Trainer are used to train a model and to tune the hyper-parameters for that model. Evaluator is used to do deep analysis of the performance of our model. We'll talk about what we mean by deep analysis a little bit later. Infra Validator is used to make sure that we can actually run predictions using our model on the infrastructure that we have. For example, do we have enough memory? If all of that passes and the model actually performs better than what we might already have in production. Then Pusher pushes the model to Production. What does that mean? Well, we might be pushing to a repository like Tensorflow HUB and then using our model later for maybe transfer learning or generating Embeddings. We could be pushing to TensorFlow JS If we're going to be using our model in a web browser or a Node.js application. We could push to TensorFlow Lite and use our model in a mobile application or on an IOT device. Or we could push to TensorFlow Serving and UserModel on a server or maybe a serving cluster. The key points here, first of all, Production ML Pipelines are more than just ML code. They're ML development and software development and a formalized process for running that sequence of tasks end to end, in a maintainable and scalable way.
Its your data and your model is only going to be good as good as the quality of your data.
You don't just collect data once you are going to collect data throughout the lifetime for a particular problem, so you need a proper data pipeline where you can automate the task. Then you also need to monitor data collection all this is done to ingest and prepare data. The data will have noise and may have noisy label so you need to clean is as well, all this process should be done seamlessly.

I will not go into the detail of software 1.0 vs software 2.0, well the code is important all we care about in software 2.0 is optimization, we care about maintainability and scalability. And hence data quality is really critical for success, so in some ways you could look at it as, data is almost like the software almost like a code in a software = Data in ML
No matter how big the data is if it doesn't have any predictive content the model is not of any use. And just like that, you will have Garbage in Garbage out. So data collection is an important and critical first step to building ml systems and data.

Learn more about Data defination Here
Let’s look at a problem statement where an application suggests runs to runners, there are different runners for different level of fitness typically it’s an athletic app. The first step is to understand the user behaviours and based on that system is going to suggest runs based on their behaviour. The goal is improve consistence and sort of motivate user to accomplish task and feel happy about it.

- [ ] Data quality
- [ ] What kind of data and how much data.
- [ ] How often do you need data
- [ ] When do you expect things to change
Note: We need to first understand the user because otherwise we run the risk of collecting a bunch of data that is really just garbage. But once we understand the user, then we need to translate the user needs into data needs. We're going to do that with identifying what the data is, what the features are and what the labels are.
- [ ] Where to get the data, on going basis.
- [ ] Is there predicted value in your data.
- [ ] How consistent is data, values, units & data types.
- [ ] Outliers and errors
Internet is one of the common place of data generation, everyday data is uploaded in form of videos, sounds, pictures, text etc. and through that it we face challenges like Dataset Issues. One such less familiar type data type you get from is sensors. Take for example mobile which comes with handful of sensors or Self driving cars which collects different types of data form sensors like LIDAR, Camera, Motion sensor, GPS etc... When we working with these types of data we face challenges like:
- [ ] Inconsistent formatting
- [ ] Compounding errors from other ML models. (If output is from ensemble model, if there's error, compound that error, try to use in downstream model.
- [ ] Monitoring data source (24x7) for system issues and outages.
- [ ] Intuition about the data can be misleading
- [ ] Feature Engineering helps to maximize the predictive signals
- [ ] Feature selection helps to measure the predictive signals.
Labelling Data
Case Study:
Imagine you are running an sports analytics company your model basically gives track the player performance for optimal result. And suddenly your prediction worsens on particular skills. Before you start questioning how, why and what! lets question this; whether you put good practices into production setting. You need to think about how you're going to detect problems early. And what are the possible causes are so that you can look for those and monitor your system. And then try to have methods systems in place to deal with those problems when they happen because they probably will happen at some point.
But what kinds of problems?
| There are two different category | :-------------------------------------------------: | SLOW PROBLEMS - For Ex: Data will drift as the world changes| | FAST PROBLEMS - For Ex: Sensors|
GRADUAL PROBLEMS
| DATA CHANGES | WORLD CHANGES | SUDDEN PROBLEM | SYSTEM PROBLEM | ||
|---|---|---|---|---|---|
| * Trend & seasonality | Style Changes | Bad sensor | Bad Software Update | ||
| * Distribution of feature changes | Scope and processor changes | Bad Log data | Loss of Network connectivity | ||
| * Relative importance of feature changes | Competitor changes | Manipulation with sensors, moved or disabled | System Down | ||
| Business Expands to other geography | Bad Credentials |
Data and concept change in production ML
If you are tired, sorry but this one is going to be interesting. After deployment your job isn't over, deployed models are still vulnerable to issues like Data Change and Concept Change or World change. You will come across with different types of Ground truth changing and then your data science problems have different kinds of difficulty levels and some are really the tough ones, and based on the difficulty level your approach changes.
Detecting problems with deployed models:
Look at the data and the scope of the data and monitor your models to find problems ASAP. A fundamental issue is changing ground truth. What that means is that you need to label new data over the life of your application. It depends on really the domain that you're working in and the kinds of problems that you're trying to solve as far as what approaches are really feasible for doing that.
Problems where the ground truth really changes faster. Things like fashion. The world changes on a matter of maybe weeks; model retraining in that case is usually driven by declining model performance, which you need to measure if you're going to be aware of. Look into Model improvements, gathering better data and the software systems you're running on. But as these things get harder, you get more variables and declining model performance is one of those. Labelling in this case:>direct feedback either from your system or from your user. > Second, Crowd based human labelling.
Problems like cats and dogs classifier the ground truth really changes pretty slowly. Model retraining in those cases is usually driven by model improvements, changing model libraries or some changes in software too. Labelling in this case is fairly simple.
 Stock market falls into the category where the ground truth changes really fast, like on order of days or hours or even minutes and these kind of problems can really give you very tough times. In this case, declining model performance is definitely going to be a driver for when you need to retrain your model. You can also have things like model improvements, better data and changes in software. But those tend to be things that you'll be working on offline while you're keeping your application running. It's really model performance where you really need well-defined processes to deal with those changes. Labelling in this case becomes very challenging. Direct feedback is great if you can do it in your domain.
Stock market falls into the category where the ground truth changes really fast, like on order of days or hours or even minutes and these kind of problems can really give you very tough times. In this case, declining model performance is definitely going to be a driver for when you need to retrain your model. You can also have things like model improvements, better data and changes in software. But those tend to be things that you'll be working on offline while you're keeping your application running. It's really model performance where you really need well-defined processes to deal with those changes. Labelling in this case becomes very challenging. Direct feedback is great if you can do it in your domain.
- [ ] PROCESS FEEDBACK (DIRECT LABELLING)
- [ ] HUMAN LABELLING
- [ ] SEMI SUPERVISED LABELING
- [ ] ACTIVE LEARNING
- [ ] WEAK SUPERVISION
Focusing on 1st 2
Process Feedback
Works like recommender system or click-through rates; Actual versus predicted click-through rates. Given a recommender system did they actually click on things that you recommend? If yes, you can label it positive, if they didn't you can label it negative.
Human Labelling
Humans look at data and apply labels to them. For example, appointings doctor and radiologist to label MRI images.
Continuing with Direct labelling; It is continuous creationg of dataset.
- A way of continuously creating new training data tha you are going yo use to retrain your model.
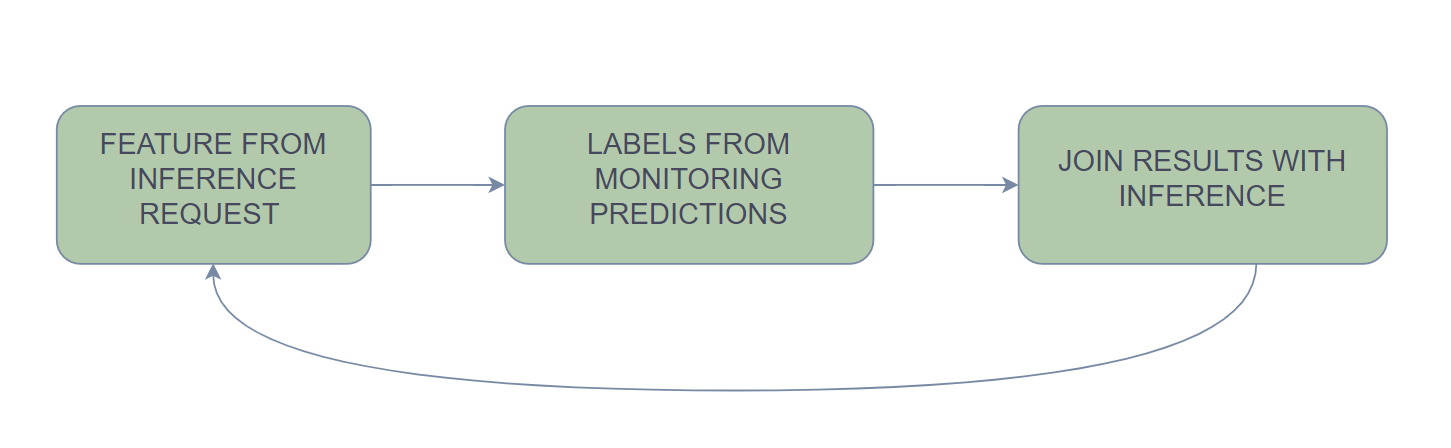
You are taking the features themselves from the inference request that your model is getting, the predictions that your model is being asked to make and the features that are provided for that. You get labels for those inference requests by monitoring system and using the feedback from those systems to label the data.
from IPython.display import display, Math, Latex
Overtime many models start to perform poorly this is called model decay. Often cause by drift, changes in statistical properties of the features seasonality or events or changes in world.
Drift Changes in data overtime, such as data collected once. Skew Difference between two static versions, or different sources, such as training set and serving set.
PERFORMANCE DECAY
Concept drift change in statistical properties of labels overtime
$${y \ne \hat y}$$
- [ ] Training and serving data do not confirm to the schema
- [ ] Dataset shift --- Covariate or concept shift
- [ ] Requires continuous solution
| TRAINING SHIFT | SERVING | |||||
|---|---|---|---|---|---|---|
| Joint | $${P_{train}(y,x)}$$ | $${P_{serve}(y,x)}$$ | ||||
| Conditional | $${P_{train}(y | x)}$$ | $${P_{serve}(y | x)}$$ | ||
| Marginal | $${P_{train}(x)}$$ | $${P_{serve}(x)}$$ |
COVARIATE SHIFT Change in distribution of input variables present in training & serving data.
Marginal distribution is not the same during training & serving. But conditional is unchanged.
-
$${ \ P_{train}(y|x) = P_{serve}(y|x) }$$
-
$${P_{train}(x) \ne P_{serve}(x)}$$
CONCEPT SHIFT refers to change in input and output variable as oppose to to data distribution itself. Conditional distribution of y is not the same during training and serving is not the same. But marginal distribution x is unchnaged(features)
-
$${ \ P_{train}(y|x)\ne P_{serve}(y|x) }$$
-
$${P_{train}(x) = P_{serve}(x)}$$